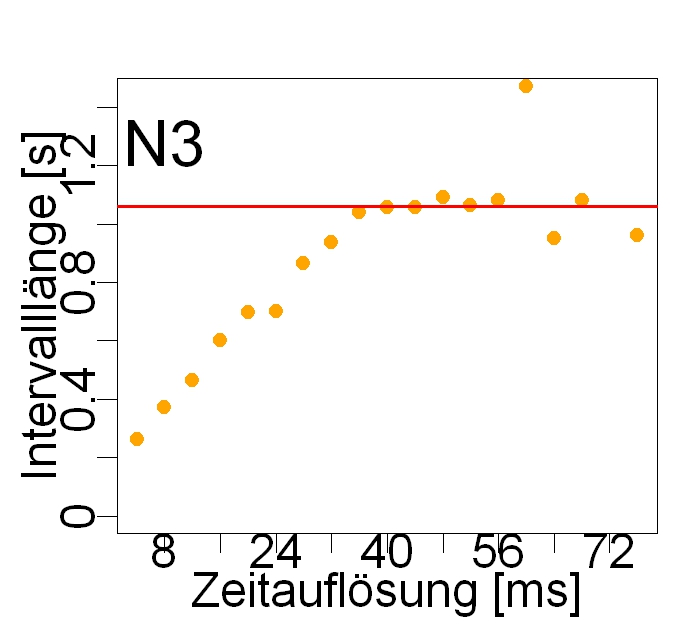
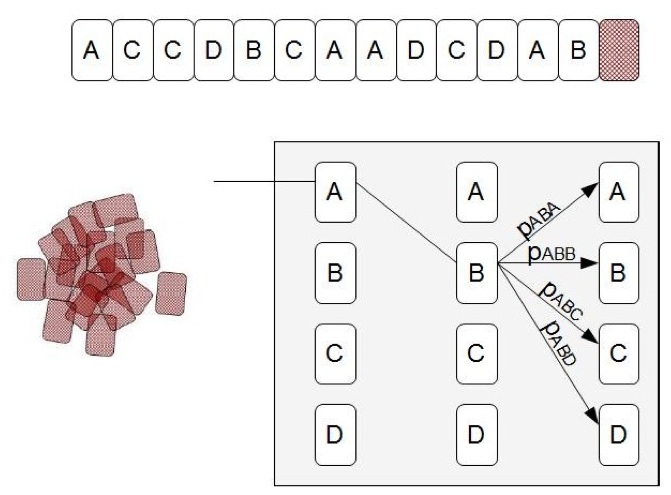
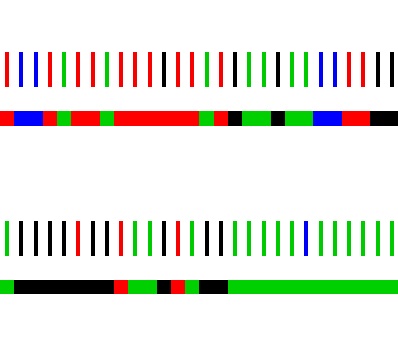
Statistisches Praktikum im SS 2012
Seminarthema: "Hirnaktivität im Schlaf"
Dr. Gaby Schneider, unter Mitarbeit von Markus Bingmer und Michael Messer
in Kooperation mit Dr. Verena Brodbeck und Dr. Helmut Laufs, Zentrum für Neurologie und Neurochirurgie
| Wann: Wo: Beginn: Vorbesprechung: Abschlusspräsentation: |
Mi. 12:15 Uhr Seminarraum 711 (groß), Robert-Mayer-Str. 10 18.4.2012 Mittwoch, 25. Januar 2012, 10:15 Uhr, Raum 711 (groß) Ankündigung Mittwoch, 4. Juli 2012, ab ca. 12 Uhr, 711 (groß), RM 10 |
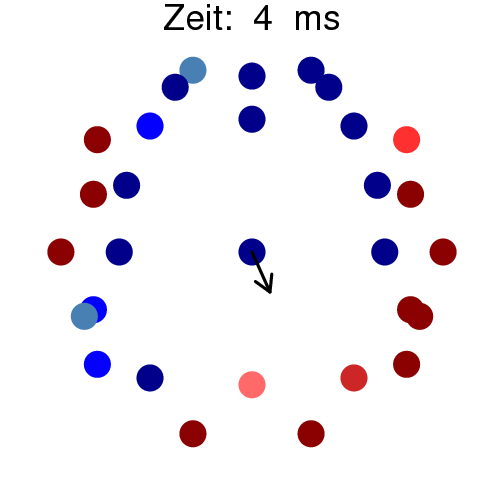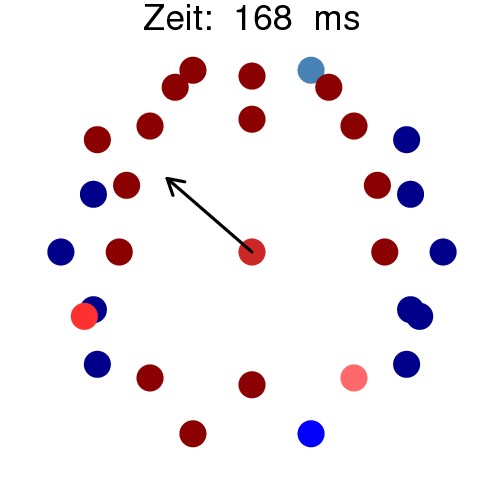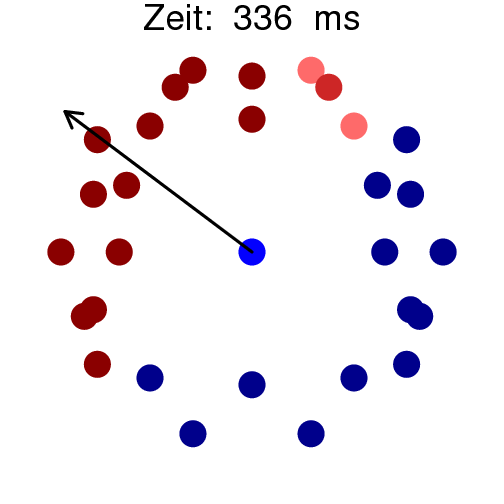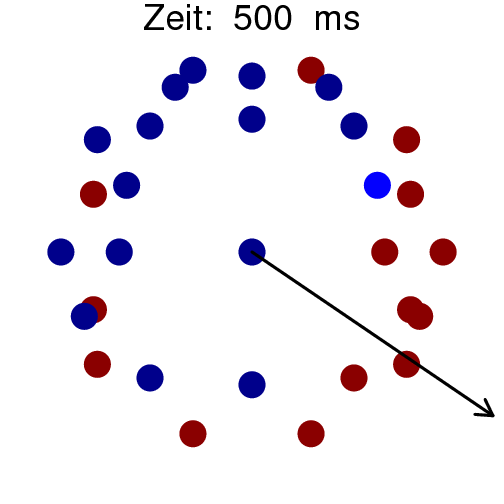
|